
What is Vector Database? Concepts and examples
Vector databases, adept at handling complex, high-dimensional data, are revolutionizing data retrieval and analytics in the business world. Their efficiency in performing similarity searches makes the

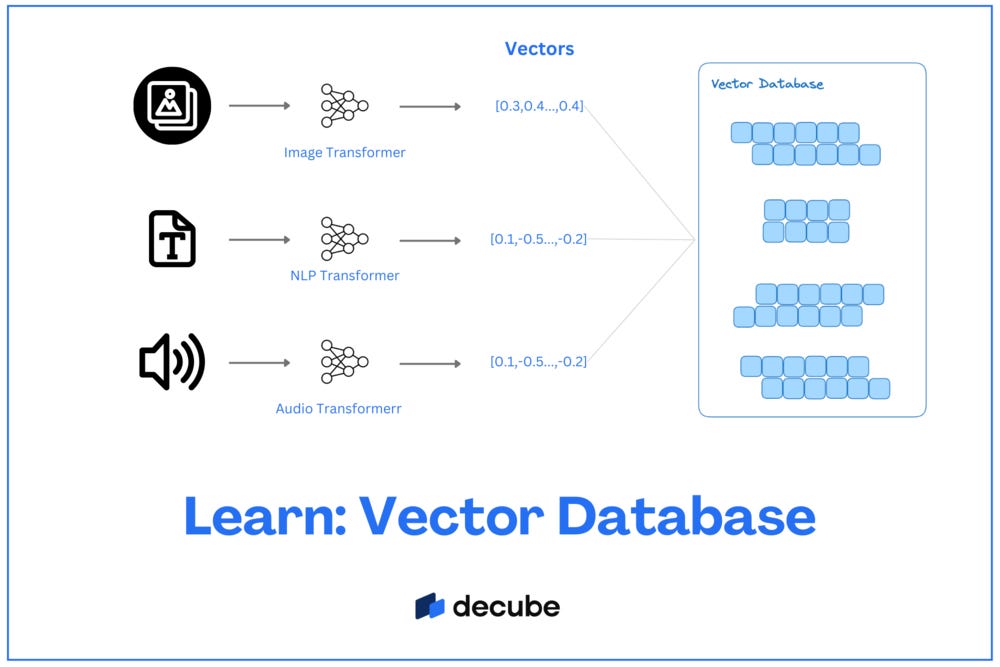
Introduction
In the world of data engineering, the term 'vector database' is increasingly becoming a buzzword. Yet, despite its prominence, many may not completely grasp its concept, functionalities, or implications for the business world. This article aims to provide an in-depth look at vector databases and delve into how they can drive significant transformations in how businesses handle data.
The Concept of Vector Databases
To begin, let's first understand the concept of vector databases. They represent a type of database management system (DBMS) designed to store, manage, and retrieve vectorized data effectively. Unlike traditional databases that work with scalar values, vector databases handle multidimensional data or vectors. Vector databases have found their niche in large-scale machine learning applications, particularly in recommendation systems, semantic search, and anomaly detection, where they deal with high-dimensional vectors.
The Mechanics of Vector Databases
The power of vector databases lies in their unique data indexing and query techniques. To reduce the time taken to retrieve similar vectors, vector databases do not iterate over every vector in the database. Instead, they use specific indexing techniques, such as KD-Trees, Hierarchical Navigable Small World graphs (HNSW), or Inverted Multi-Index (IMI), to organize vectors in such a way that the search space can be significantly reduced during queries.
During a query, these databases identify the region of the vector space where the similar vectors are likely to reside and search only within that region. This approach dramatically reduces the computation time required to retrieve similar vectors, making vector databases extremely efficient for similarity search tasks.
Advantages of Vector Databases
Vector databases are engineered to perform high-speed similarity searches in massive datasets. They excel in vectorized data because they leverage unique data indexing and query techniques that significantly reduce the search space, speeding up the retrieval process. Vector databases are efficient in handling complex data structures, making them ideal for advanced machine learning applications.
Querying a Vector Database
Now let's delve into querying vector databases. Although it might seem daunting at first, it's quite straightforward once you get the hang of it. The primary method of querying a vector database is via similarity search, using either Euclidean distance or cosine similarity.
Here's a simple example of how to add vectors and perform a similarity search using a pseudo-code:
# Import the vector database library
import vector_database_library as vdb
# Initialize the vector database
db = vdb.VectorDatabase(dimensions=128)
# Add vectors
for i in range(1000):
vector = generate_random_vector(128) # generate_random_vector is a function to generate a random 128-dimensional vector
db.add_vector(vector, label=f"vector_{i}")
# Perform a similarity search
query_vector = generate_random_vector(128)
similar_vectors = db.search(query_vector, top_k=10)
In the above code, the db.add_vector(vector, label=f"vector_{i}") method is used to add vectors to the database, and the db.search(query_vector, top_k=10) method is used to perform a similarity search.
Applications in the Business World
In the business world, vector databases offer significant potential for a variety of applications, driving transformations in how businesses handle, analyze, and derive insights from data.
1. Recommendation Systems
Businesses with e-commerce platforms can use vector databases to power their recommendation systems. These systems use vectors to represent both users and items (such as products), and the similarity between these vectors can determine the items to recommend to a user.
2. Semantic Search
In information retrieval and natural language processing (NLP), vector databases can improve the efficiency and accuracy of semantic searches. By converting text data into vectors using techniques like word embeddings or transformers, businesses can use vector databases to search for similar words, phrases, or documents.
3. Anomaly Detection
Vector databases can be used in security and fraud detection, where the goal is to identify anomalous behavior. By representing normal and anomalous behavior as vectors, businesses can use similarity search in vector databases to quickly identify potential threats or fraudulent activities.
4. Personalized Marketing
In today's competitive business landscape, personalized marketing is a key differentiator. Businesses can use vector databases to profile customers based on their interactions and behavior, subsequently offering them customized services and products. For instance, browsing history, social media activity, and past purchases can be represented as vectors in a high-dimensional space. By identifying patterns and clusters in this space, businesses can understand customer preferences at a granular level and target them with personalized marketing campaigns.
5. Image Recognition
Vector databases play a critical role in the field of image recognition, where images are converted into high-dimensional vectors using techniques like convolutional neural networks (CNN). For instance, a face recognition system may store the vector representations of faces in a vector database. When a new face image is introduced, the system can compare it against the vectors in the database to find the most similar faces.
Here's a simplified example of how to perform image search using a pseudo-code:
# Import the vector database library
import vector_database_library as vdb
import image_to_vector as iv # Assume this is a function that converts images to vectors
# Initialize the vector database
db = vdb.VectorDatabase(dimensions=512)
# Add image vectors
for image in image_dataset:
vector = iv.image_to_vector(image)
db.add_vector(vector, label=image.name)
# Perform an image search
query_image = "new_image.jpg"
query_vector = iv.image_to_vector(query_image)
similar_images = db.search(query_vector, top_k=10)
6. Bioinformatics
In bioinformatics, vector databases can be used to store and query genetic sequences, protein structures, and other biological data that can be represented as high-dimensional vectors. By finding similar vectors, researchers can identify similar genetic sequences or protein structures, helping to advance our understanding of biological systems and diseases.
Vector Databases in Practice: Platforms and Use Cases
While the use of vector databases is burgeoning, several platforms have emerged as frontrunners. These platforms include Milvus, Pinecone, and Weaviate, each of which offers a unique set of features tailored to different use cases.
Milvus, an open-source vector database, is designed for AI and analytics workloads. It enables similarity search at scale and supports heterogeneous computing, making it well-suited for machine learning applications, such as semantic search and recommendation systems.
Pinecone, on the other hand, is a managed vector database service that abstracts away the complexities of infrastructure and scaling. It's designed for real-time applications and can handle large-scale data without compromising on performance or accuracy.
Weaviate is an open-source vector search engine with a GraphQL API. It enables users to run similarity searches on their data using a simple and intuitive query language.
Sample Code using Milvus:
Code for: Image recognition system
# Import the Milvus library
from pymilvus import connections, DataType, CollectionSchema, FieldSchema, Collection
# Establish a connection to Milvus
connections.connect("default")
# Define the collection schema
dim = 512 # Dimension of the vector
collection_name = "image_recognition"
collection_schema = CollectionSchema(
fields=[
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="image_vector", dtype=DataType.FLOAT_VECTOR, dim=dim)
],
description="Collection for image recognition"
)
# Create the collection
image_collection = Collection(name=collection_name, schema=collection_schema)
# Import image_to_vector module (This module is hypothetical and would contain the function to convert image to vector)
import image_to_vector as iv
# Add image vectors to Milvus
for i, image in enumerate(image_dataset):
vector = iv.image_to_vector(image)
image_collection.insert(
[
(i,), # ID field
(vector.tolist(),) # Image vector field
]
)
# Load the collection into memory before search
image_collection.load()
# Perform an image search
from pymilvus import utility, TopKQueryResult
query_image = "new_image.jpg"
query_vector = iv.image_to_vector(query_image)
search_params = {
"metric_type": "L2", # The distance metric used, could also be "IP" for inner product
"params": {"nprobe": 10},
}
topk = 10
status, results = image_collection.search(
[query_vector.tolist()], "image_vector", param=search_params, limit=topk
)
Conclusion
The future of data-driven decision making lies in our ability to navigate and extract insights from high-dimensional data spaces. In this regard, vector databases are paving the way towards a new era of data retrieval and analytics. With an in-depth understanding of vector databases, data engineers are well-equipped to handle the challenges and opportunities that come with managing high-dimensional data, driving innovation across industries and applications.
In conclusion, whether it's personalizing the customer journey, identifying similar images, or comparing protein structures, vector databases are the engine powering these computations. They offer an innovative way to store and retrieve data, making them an essential tool for any data engineer's toolkit.